Tại sao BST không dùng cho indexing?
Khi không có index, database bắt buộc phải scan qua toàn bộ dữ liệu - điều mà ai cũng biết. Với Binary Search Tree (BST) ta không phải scan toàn bộ nữa, các operations find/insert/delete chỉ mất O(logn), quá powerful.
Vậy thì tại sao BST lại không được dùng để indexing?
Vấn đề 1
Trường hợp dữ liệu chỉ tăng/giảm dần -> Cây bị nghiêng về 1 phía, khi thực hiện operations không khác gì scan toàn bộ data 😂
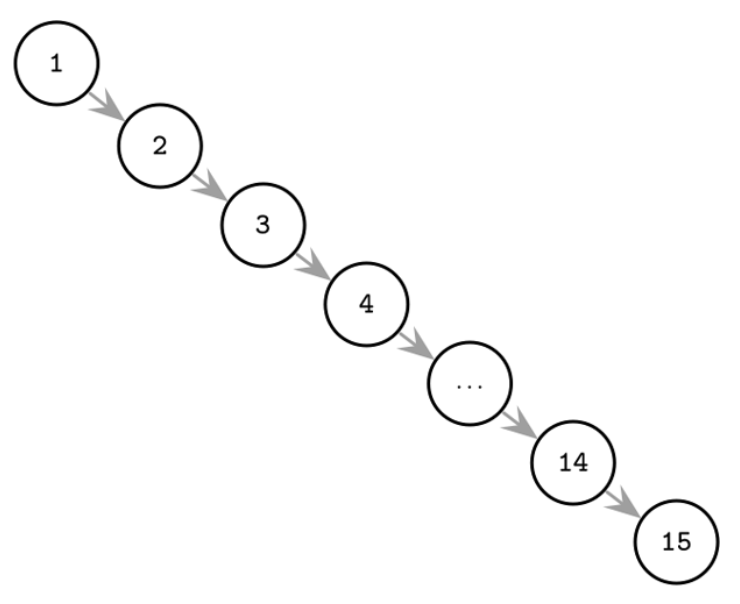
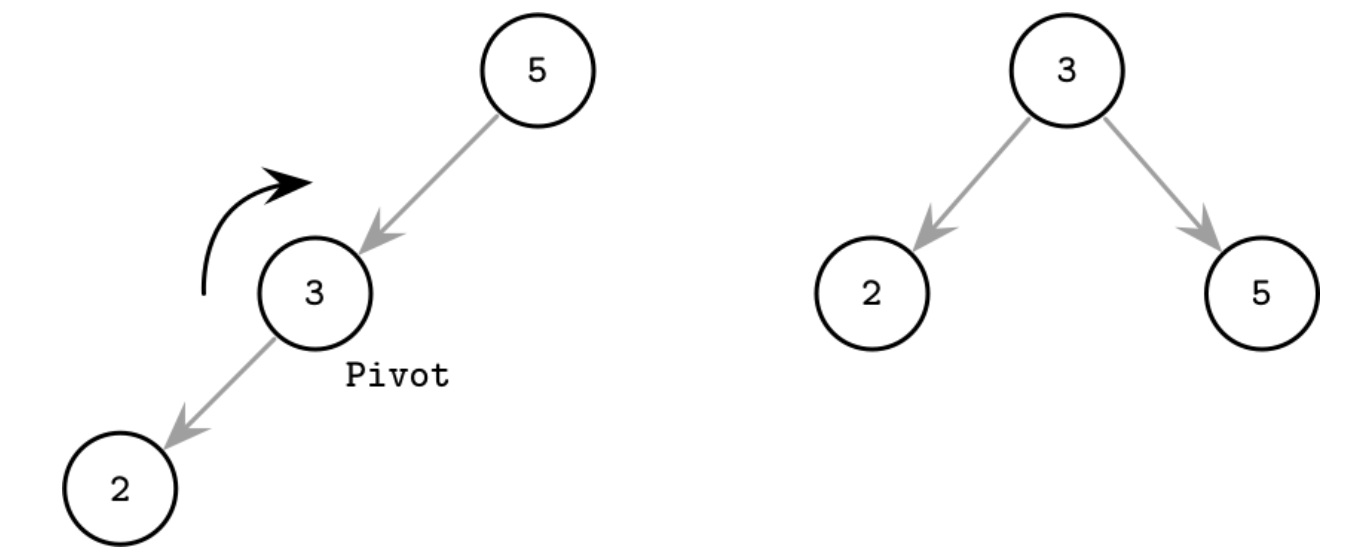
Hmm, có cách, ta có thể dùng một BST biết tự cân bằng để giải quyết vấn đề này:
Vấn đề 2
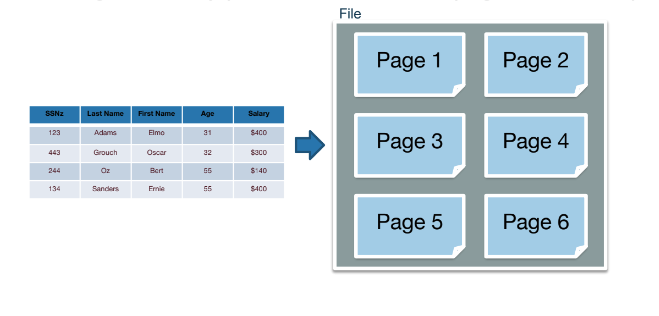
Mọi chuyện không đơn giản như thế, BST trong memory và disk là khác nhau. Trong memory ta có thể thao tác tùy thích, nhưng với disk, dữ liệu khi lưu bị chia random ra nhiều pages:
Tất nhiên vẫn có cách để cải thiện một xíu, ta có thể dùng Paged binary tree với pointers trỏ đến các nodes ở pages khác:
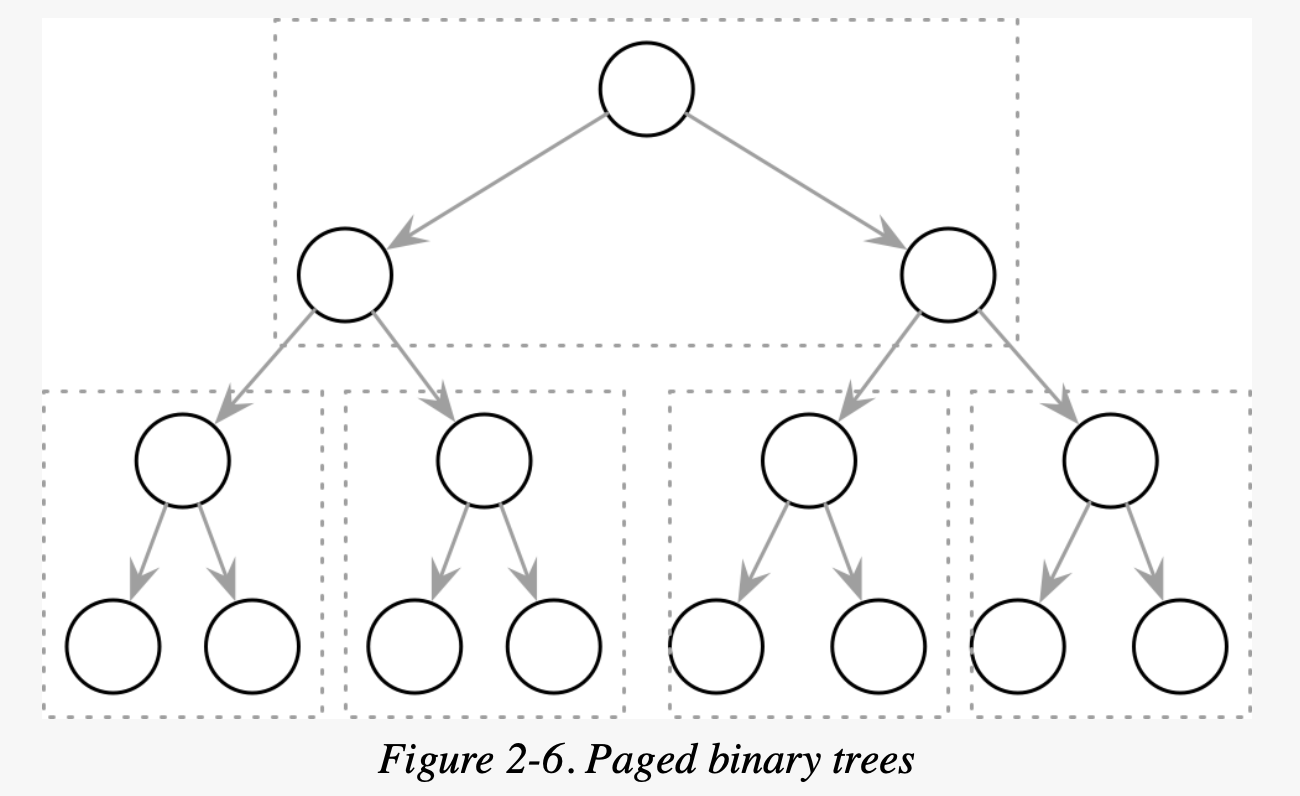
Nhưng khi dữ liệu bị thay đổi cây vẫn phải tự cân bằng lại, nghĩa là dữ liệu từ các pages phải thay đổi hết. Điều này dẫn đến thực hiện nhiều operations -> expensive.
Vấn đề 3
Fan-out (số lượng nodes con từ một node cha) quá nhỏ - tối đa chỉ có 2 nodes. Do đó, dữ liệu lưu vào bị nằm rải ra nhiều pages, dẫn đến thực hiện nhiều operations -> expensive.
Xem Paged binary tree minh họa cho phần này.
Giải pháp
Như vậy ta cần phải tìm một cấu trúc dữ liệu khác mạnh như BST, nhưng phải tối ưu 2 điểm:
- Fan-out lớn, có thể có nhiều nodes con từ một node cha
- Cây thấp thôi, hạn chế pointers trỏ đến nhiều pages (Thật ra thì chỉ cần tối ưu fan-out là cây tự thấp lại 🤥)
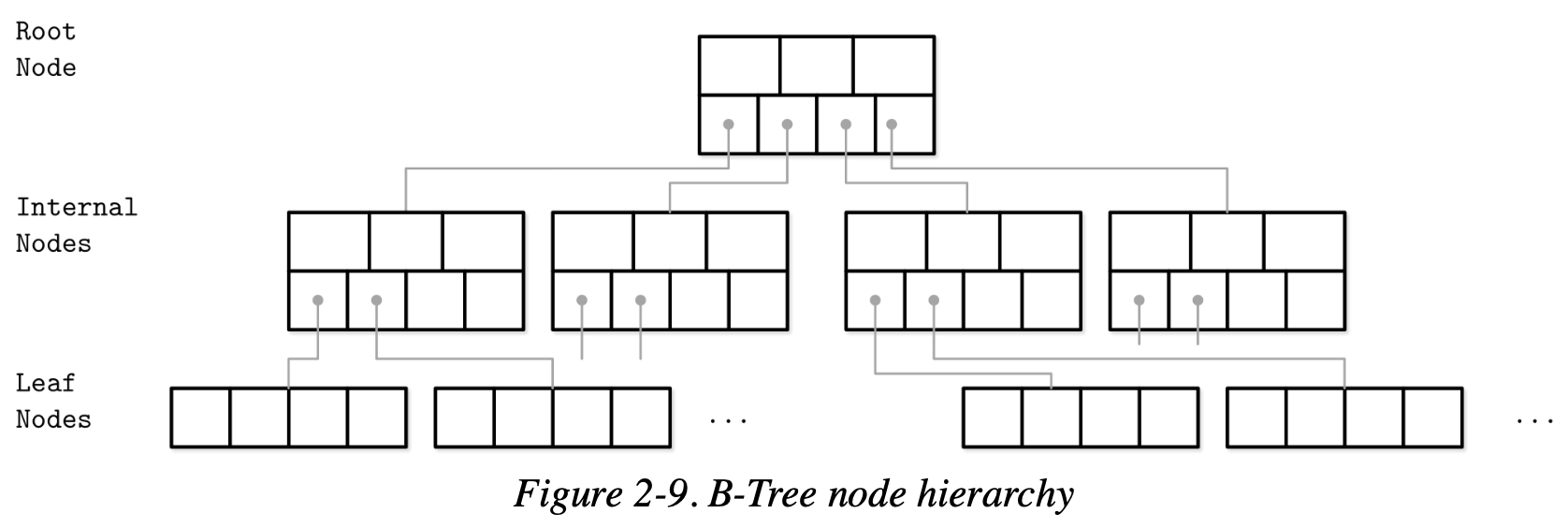
Với B-Tree ta có thể giải quyết hết các vấn đề trên:
- Fan-out lớn
- Có khả năng tự cân bằng
- Các operations find/insert/delete chỉ mất O(logn)
Lần này đến đây thôi. Như thường lệ, cảm ơn mọi người đã đọc đến đây, hy vọng nhận được góp ý từ mọi người 😊
Tham khảo thêm:
- Database Internals by Alex Petrov
- Understanding B-Trees: The Data Structure Behind Modern Databases